全国免费咨询热线
13988889999
工作时间:周一到周六 AM8:30
工作时间:周一到周六 AM8:30


CONTACT

时间:2024-07-08 14:39:49 点击量:
[ArXiv 论文地址]CAME: Confidence-guided Adaptive Memory Efficient Optimization
[代码链接]PyTorch 优化器可直接安装
在模型训练中,特别是在参数规模不断增加的大型语言模型(LLM)中,优化内存使用是至关重要的。我们提出了 CAME 优化器,与谷歌的 Adafactor 优化器一样减小了优化器的内存使用,同时保持与 Adam 优化器相同甚至更优的性能水平。
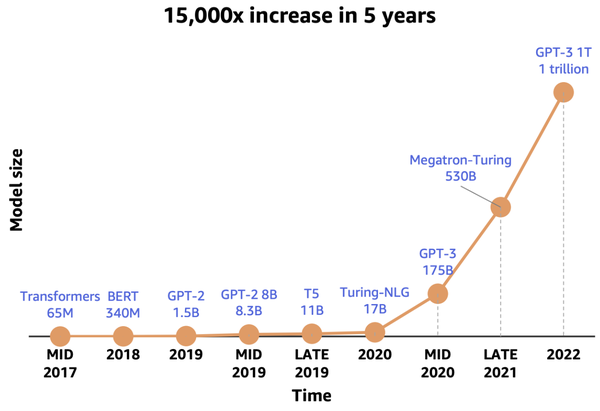
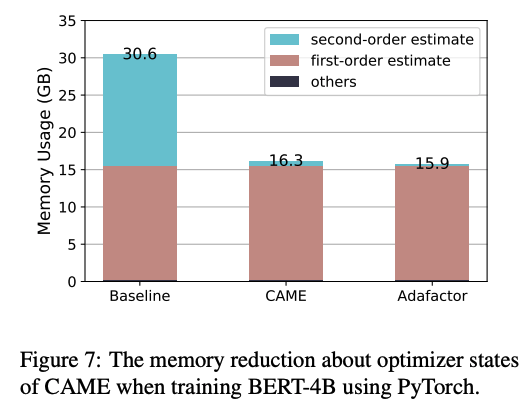
LLM中参数数量的增长显著增加了训练所需的内存。优化器在整体内存消耗中占据了相当大的比例。例如,使用Adam优化器的混合精度训练时,相比模型本身的内存使用量,需要多出6倍的内存(m、v状态和fp32副本)。
为了减少内存使用,一种有效的方法是优化优化器状态的内存占用。Google广泛使用的Adafactor优化器通过使用矩阵分解来节省二阶动量状态(v)的内存:
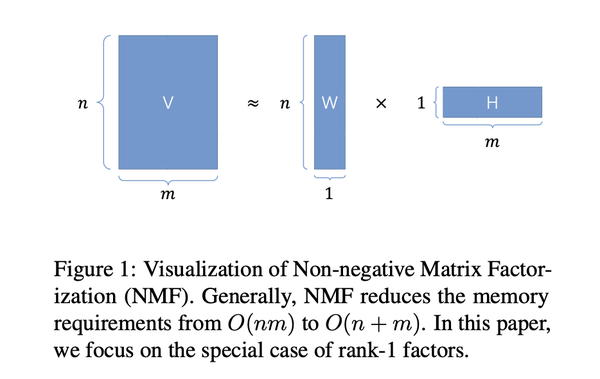
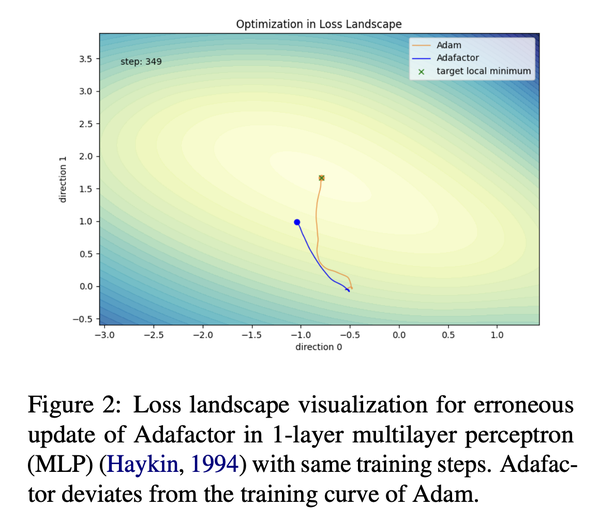
该方法可以将内存使用从O(nm)减少到O(n+m)。然而,所引入的矩阵分解导致了更新不稳定性,进一步导致在大规模语言模型预训练任务中性能下降。我们在一个多层感知器的训练任务中比较了Adam和Adafactor的优化过程,很明显Adafactor与Adam的训练轨迹有所偏离。
为了解决Adafactor存在的不稳定性问题,我们提出了CAME优化器(Confidence-guided Adaptive Memory Efficient)。CAME优化器结合了基于置信度的更新值校正。通过对引入的置信度矩阵进行非负矩阵分解,可以有效地降低额外的内存开销。CAME算法的概述如下,其中黑色字体表示与Adafactor相似之处,蓝色字体表示修改之处。

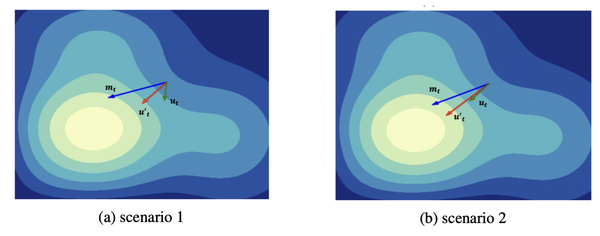
CAME与Adafactor之间的关键区别在于CAME引入了置信度矩阵,用于校正更新值。其基本原理很简单。Adafactor可能存在近似误差,导致更新出现偏差。Adafactor 中引入的更新动量可以平滑更新,起到一定效果。在CAME中,我们进一步减小与动量明显偏离的更新,并鼓励具有较小偏差的更新。下图展示了这种校正的影响。
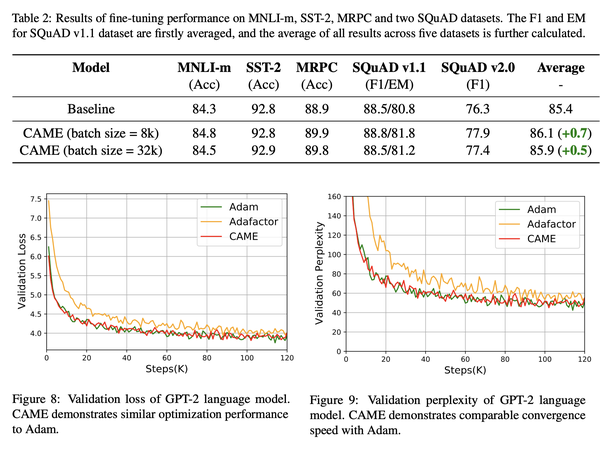
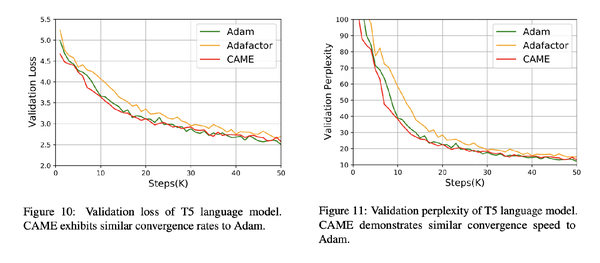
我们在多个广泛使用的大规模语言模型预训练任务上评估了CAME优化器,包括BERT和T5。结果总结如下:我们的CAME优化器优于Adafactor,在训练性能上与Adam优化器相当甚至更好,在内存使用方面与Adafactor类似,在大批量预训练场景下表现更加鲁棒。
我们正在开发一个即插即用的 CAME 优化器包,可以无缝地集成到现有的训练流程中,包括像GPT-3和LLaMA这样的流行模型。此外,我们正在努力消除Adafactor和CAME优化器中对动量状态的需求,进一步优化内存开销。
此外,随着GPU集群规模的不断增大,我们正在探索将CAME优化器应用于更大批量大小的潜力。这项研究旨在充分利用CAME在内存优化和性能提升方面的优势,以更大规模地提升效果。
地址:海南省海口市玉沙路58号 电话:0898-88889999 手机:13988889999
Copyright © 2012-2018 天辰-天辰平台-天辰中国加盟站 ICP备案编:琼ICP备88889999号






