全国免费咨询热线
13988889999
工作时间:周一到周六 AM8:30
工作时间:周一到周六 AM8:30


CONTACT

时间:2024-04-29 04:14:57 点击量:
1、 学习图像平滑功能的实现方法与平滑处理流程;
2、 学习基本的性能优化方法;
3、 修改kernels.c文件,测试每个版本的CPE;
4、 本次实验需要优化smooth函数,尽可能提高程序性能。
取相邻四个像素点的平均值;
取相邻六个像素点的平均值;
取相邻九个像素点的平均值。
scp 本地文件路径 用户名@服务器地址:/服务器路径
scp 用户名@服务器地址:/服务器路径 本地文件路径
代码移动、减少函数调用、减少访存次数、分支预测、循环展开、并行处理、cache友好等。
target …:prerequisites …
command 1
command 2
target:即目标文件,可以是Object File、执行文件、一个标签;
prerequisites:即要生成该target所需要(依赖)的文件或是目标;
command即make需要执行的命令,可以是任意的Shell命令。
注意,要执行的命令行一定要以一个Tab键作为开头。在Makefile中的定义的变量,就像是C/C++语言中的宏一样,代表了一个文本字串,Makefile中执行的时候其会自动原模原样地展开。变量在声明时需要给予初值,而在使用时,需要给在变量名前加上“$”符号,但最好用小括号“()”或是大括号“{}”。

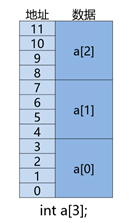
可以看到,每一个像素点占0.75个字长。
进一步分析可知,只有1/2的像素点存储在一个块中,读或写余下的像素点需要访问两个块。
内存是一维的,因此不管是一维数组、二维数据、n维数组,在内存中都是以一维的方式存储的。二维数组是以行优先的规则在内存中存储的。
说明:由于我的老师是把实验文件直接放在了服务器里并且设置好了每位同学的用户名,这里我将整个perfLab文件夹复制到本地计算机,通过本地编译器编译,以便进一步研究优化方案。如果老师是通过课程中心、通知群、邮箱等下发的实验文件,直接下载文件之后修改kernels.c就好啦!
1、 进入终端。若为Windows操作系统,按下”Windows”+”R”,输入”cmd”进入;若为Linux操作系统,在首页选择”Terminal”。
2、 输入指令” ssh 域名-l用户名”,输入密码。登陆服务器。
3、 成功登陆之后,可以通过pwd命令与ls命令查看当前所在目录与当前目录下的文件。如果需要退出登录,输入exit。
4、 在登录状态下,cd进入perfLab文件夹内,执行perf_init命令进行初始化。
5、 从服务器中拷贝文件到本地:
通过”scp 本地文件路径 用户名@服务器地址:/服务器路径”将本地文件拷贝到服务器,也可以通过” scp 用户名@服务器地址:/服务器路径 本地文件路径”将服务器文件拷贝到本地。对于文件夹的拷贝,需要在scp后加”-r”参数。
这里我先将实验文件从服务器中拷贝到本地,修改完成之后再上传回服务器。也可以直接在服务器通过vim修改文件。
6、 回到服务器,在perfLab文件夹下执行make。
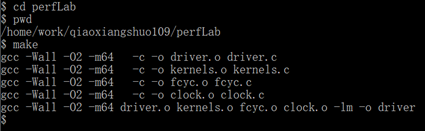
7、 输入“https://blog.csdn.net/qq_41112170/article/details/driver”命令进行评分。

关于kernels.c的优化作如下说明:
建议通过添加新版本而不是修改smooth()函数的方式进行优化。
首先,我们新增函数并在函数体内实现图像平滑处理功能,函数参数同smooth函数保持一致。比如,我新增了函数名为”smooth1”的函数:
然后,我们通过add_smooth_function()方法添加该函数版本,如:
尽管我们添加了不同的优化版本,但由于我们没有声明版本描述,因此在评分过程中,程序提示:
Smooth: Version = smooth: Current working version:
我们并不能在评分页面区分不同的版本。为解决这一问题,我们需要声明版本描述:
首先,在新增函数之后,我们定义一个字符数组,并令其初值为我们想要的版本描述信息。如:
然后,我们将add_smooth_function()方法的第二个参数改为字符数组名,如:
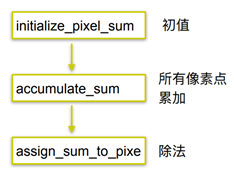
naive_smooth()函数调用了avg()函数,我们分析一下avg()函数的内容:
在naive_smooth()函数中,按顺序对src中每个像素点调用avg()函数,将返回值保存在dst的对应位置。在avg()函数中,ii与jj选择像素点,通过accumulate_sum()函数累加,通过assign_sum_to_pixel()函数得到平均值,最后将结果current_pixel返回。可以看到这里存在过多的函数调用,如在每次for循环内都调用一次min()或max()函数,因此可以预料到效率很低。
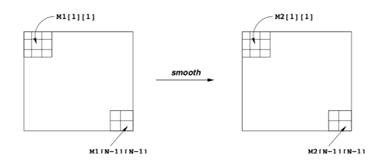
考虑到虽然不同位置的像素点需要取相邻的不同数目的像素点的平均值,但数目只有4、6、9。
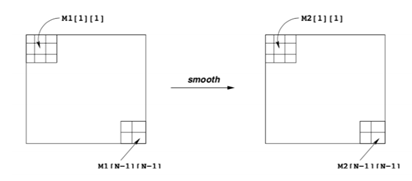
结合上图,分析可知:对于四个顶点,我们需要取相邻四个像素点的平均值;对于除顶点外的四条边上的像素点,我们需要取相邻六个像素点的平均值;对于其他像素点,我们需要取相邻九个像素点的平均值。
我们按照行访问顺序,针对不同的求平均值的情况分开处理,即独立计算不同位置的像素点,从而将所有除法运算由除变量改为除常量。在此基础上,我们还可以尽可能消除函数调用。如下图所示:

核心代码如下:
继续分析,可以发现上面的程序性能仍然存在问题。虽然在前一个版本中,我尽可能地消除了函数调用,将待平均像素点数目判断由max()、min()、计数器的方法改为代码直接指定的方法,但出现了程序运行过程中比较多的重复计算量。如下图所示,蓝色部分为重复计算区域:

我基于动态规划的思想,将每一个像素点的计算转换为一个块(2x2或2x3或3x2或3x3)内的各个像素点取平均值,并将每一块纵向分开为2或3个纵向块,用动规数组记录每一列(2个或3个像素点)的R、G、B之和。相邻的两个纵向块之间存在递推关系,通式可以表达为:
dp[i][j]=dp[i-1][j]-src[(i-1)*dim+j]+src[(i+2)*dim+j]
核心代码为:
这样处理虽然以“用空间换时间”的方式减少了总计算量,但不难看出由于递推关系为纵向,因此读运算的空间局部性较差,产生了大量的不命中。此外,二维数组的选择似乎也不够合理。因此,可以将递推关系改为横向,再次尝试。我同时想到了通过指针尽可能小范围移动的方法,继续尝试第三个版本。
基于版本一的行优先读写顺序,考虑到对于任何像素点,待求平均的像素点所构成的块大小都不会超过三行,每行都不会超过三个。这启发我可以通过三个指针,每个指针控制行相邻的两个或三个像素点的读运算。核心代码为:
版本一与版本二给了我启发:版本一将处理方式不同的位置分别讨论,但大量的重复计算限制了性能的进一步提升;版本二采用动态规划的思想,但不合理的子问题(纵向三个像素点的R、G、B之和)与二维数组的选择不够合理,导致性能提升并不理想;版本三使用指针的思想同样值得推广。
结合版本一、版本二与版本三的优缺点,便有了版本四。版本四每次使用了六个临时变量存储结果,1~6分别为(i,j)、(i,j+1)、(i,j+2)、(i+1,j)、(i+1,j+1)、(i+1,j+2)所对应的向下三个像素点的R或G或B之和。核心代码如下:
1、 未进入perfLab文件夹导致无法make

解决方法:导致该问题的原因是没有在指定的文件夹下执行make,解决方法为cd进入perfLab文件夹,再执行make。
2、 代码出现细节上的错误
在写版本二时未仔细检查,评分时出现:

考虑到版本二中使用了动态规划数组,结合报错信息,推测大概率是数组访问越界。经检查,出错原因为r2、g2、b2定义为int[2][dim],数组第一行对应dst第一行,数组第二行对应dst最后一行,在使用时却视为了int[dim][dim],直接使用了r2[i][j],导致出现段错误。这提醒了我,对于一些符号的定义一定要明确,避免出现前后含义不一致的情况。
写在最后:
如果觉得这篇博客帮到了你,请给博主点一个大大的赞!
地址:海南省海口市玉沙路58号 电话:0898-88889999 手机:13988889999
Copyright © 2012-2018 天辰-天辰平台-天辰中国加盟站 ICP备案编:琼ICP备88889999号






